Subsurface-Offset Image Volumes
Extended Imaging, Velocity Analysis, and the Road to FWI
2026-04-01


Subsurface Image Volumes and Migration Velocity Analyses
Felix J. Herrmann
School of Earth and Ocean Sciences — Georgia Institute of Technology
Based on Hou and Symes (2015), Hou and Symes (2016), and Hou and Symes (2018).
William W. Symes

Noah Harding Professor Emeritus
Computational & Applied Mathematics, Rice University
- Founded The Rice Inversion Project (TRIP) — 25+ years of industry-sponsored research
- Pioneered differential semblance optimization for migration velocity analysis
- SIAM Fellow; Desiderius Erasmus Prize (EAGE, 2015); Ralph E. Kleinman Prize (SIAM)
- Key insight: use the approximate inverse (not the adjoint) for velocity analysis
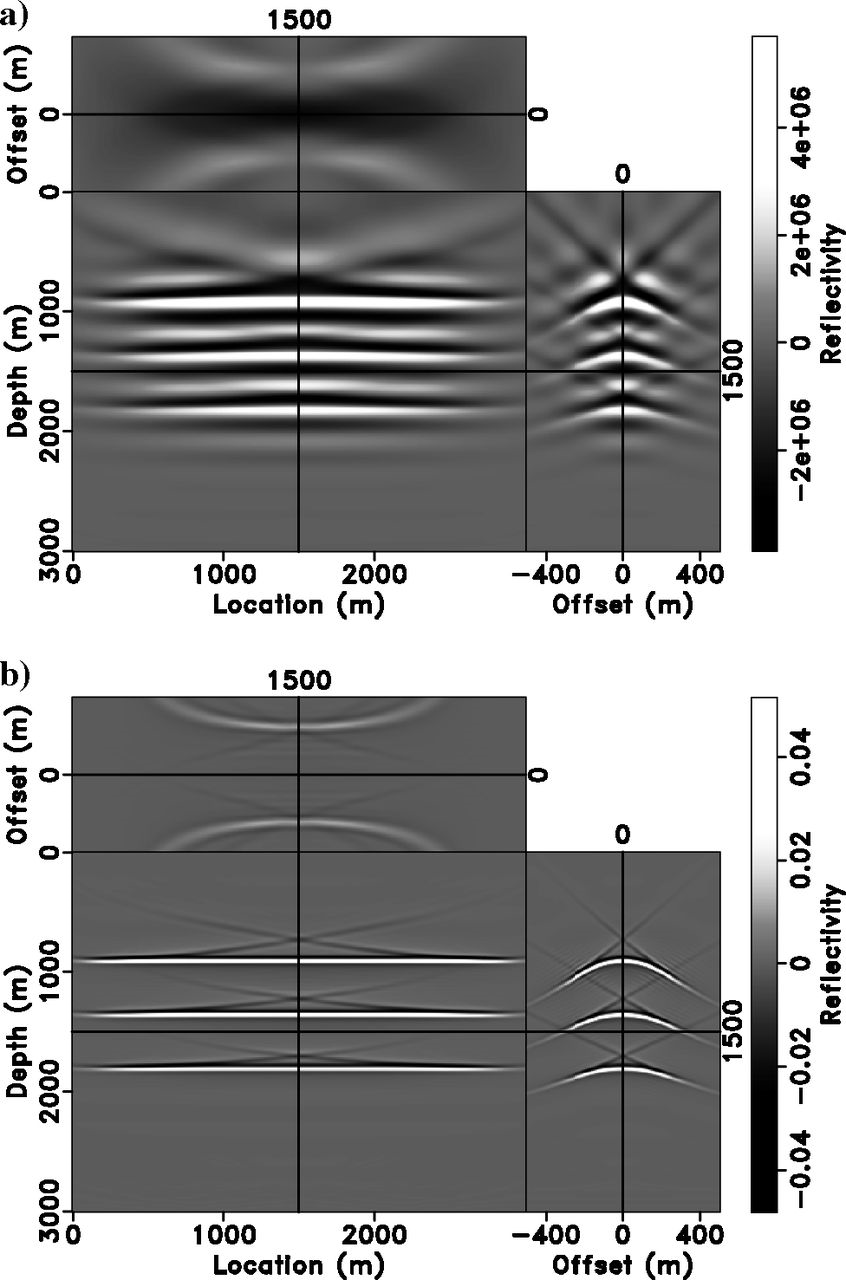
Subsurface Offset — The Idea
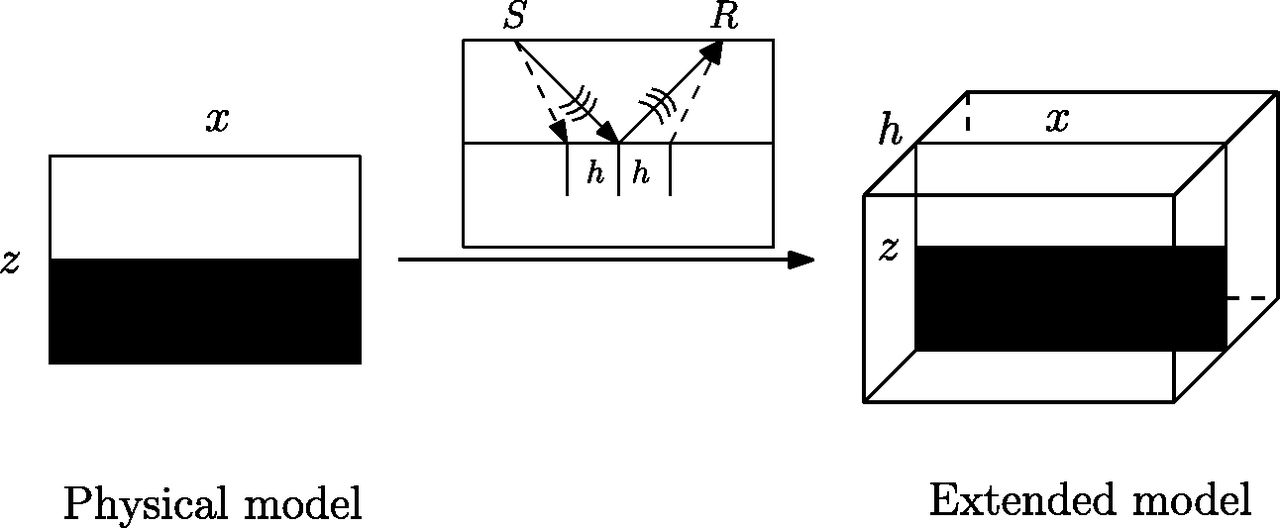
Sketch of the subsurface offset extension. The subsurface offset \(h\) is half the distance between subsurface scattering points. This extension allows stress to produce strain at a distance (Hou and Symes 2016).
What Focusing Tells Us
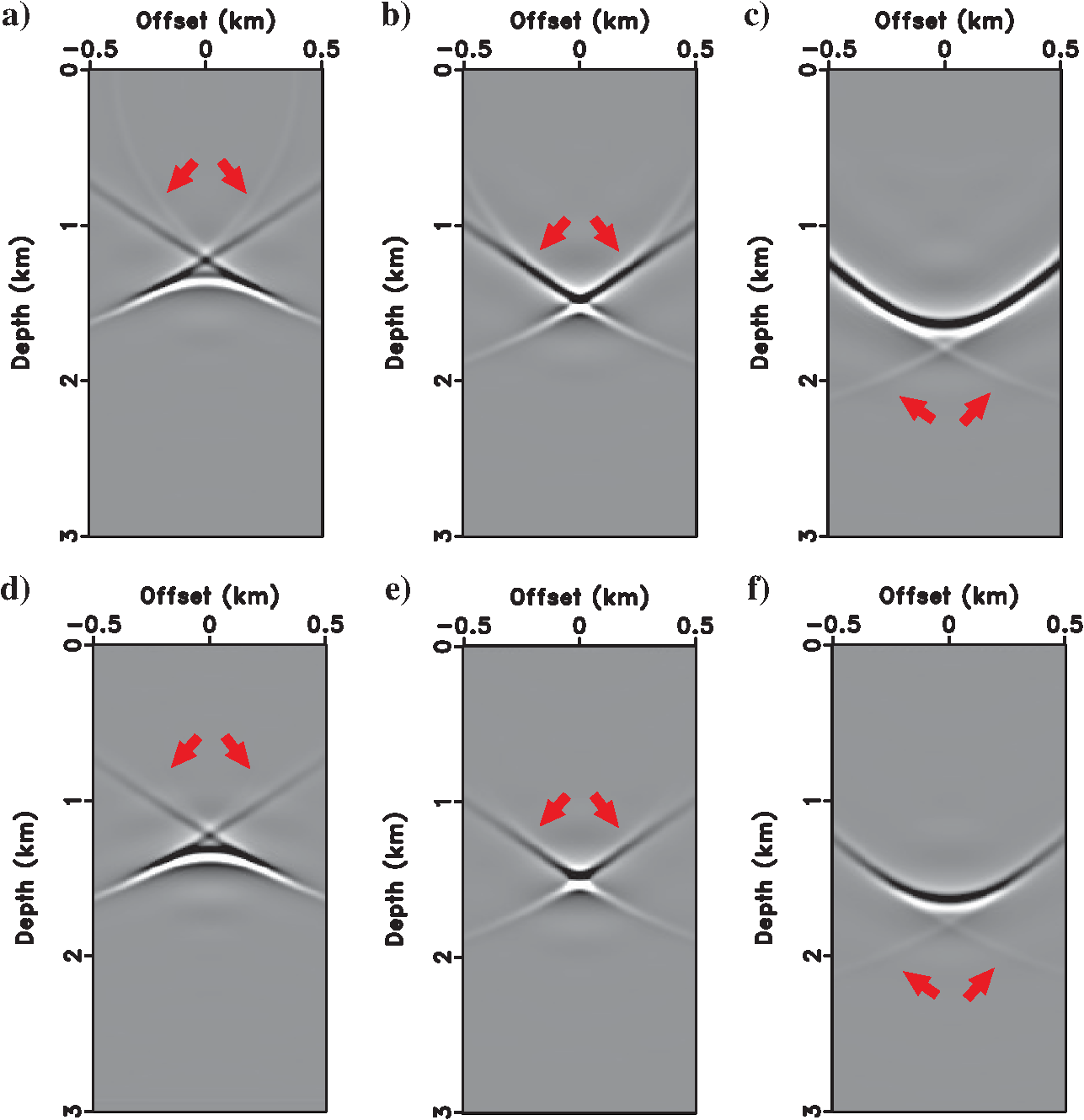
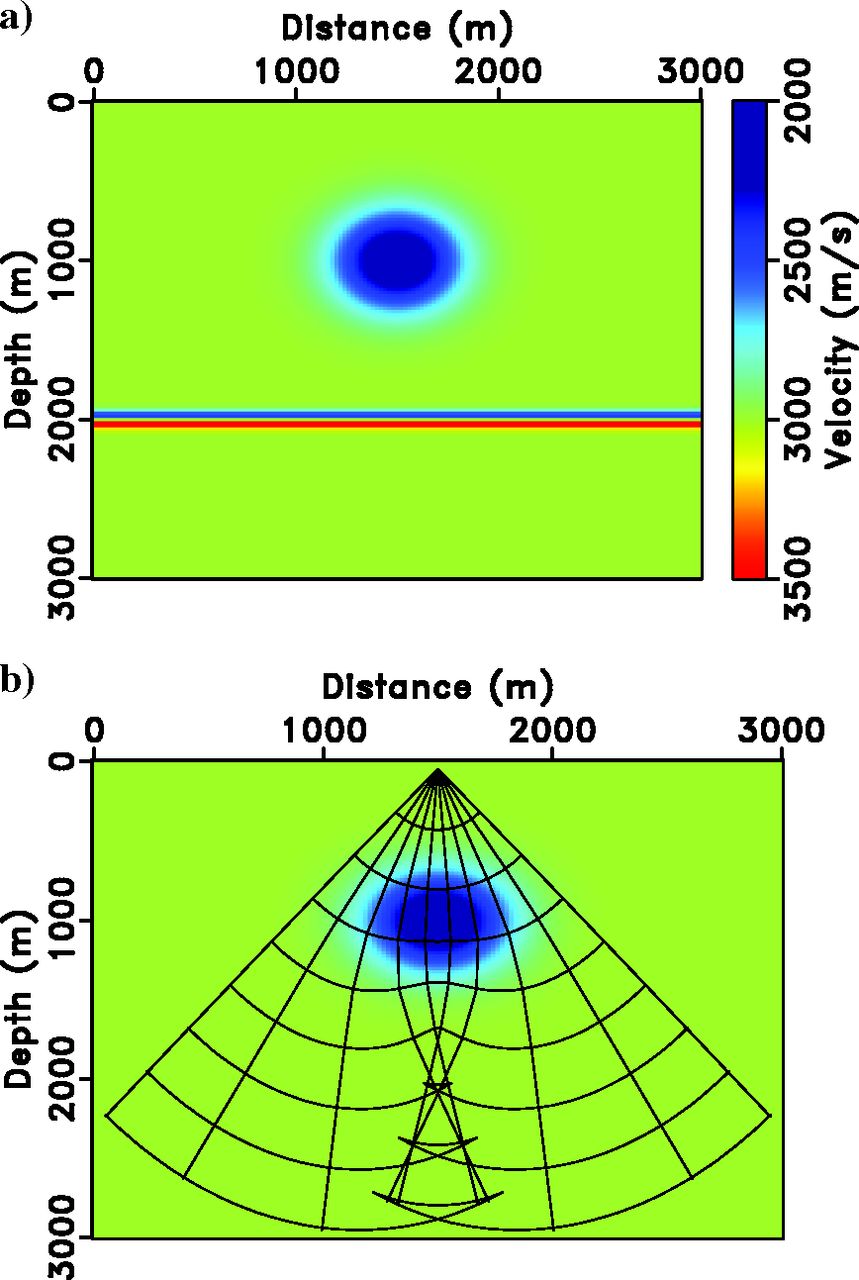
Paper A: Simple Model Setup
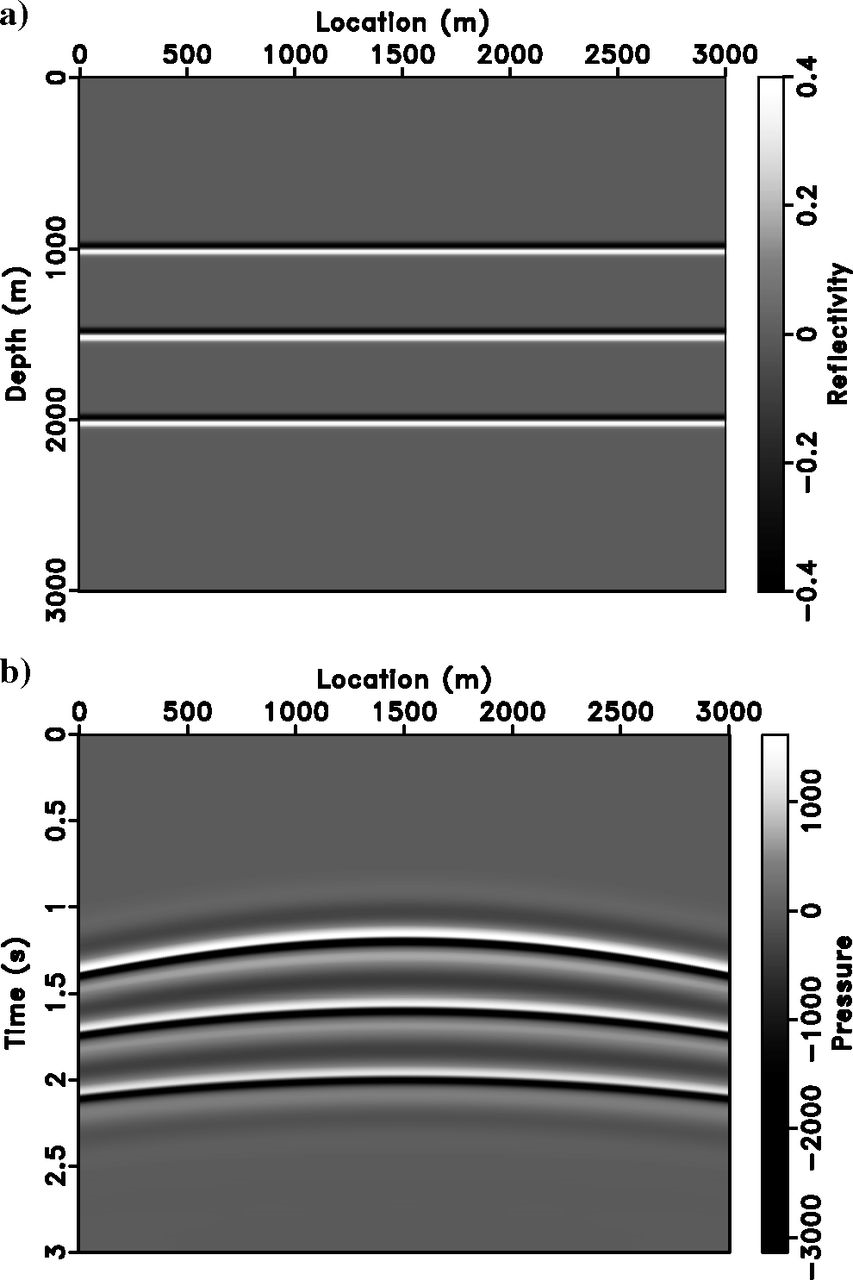
Extended RTM vs. Extended Inversion
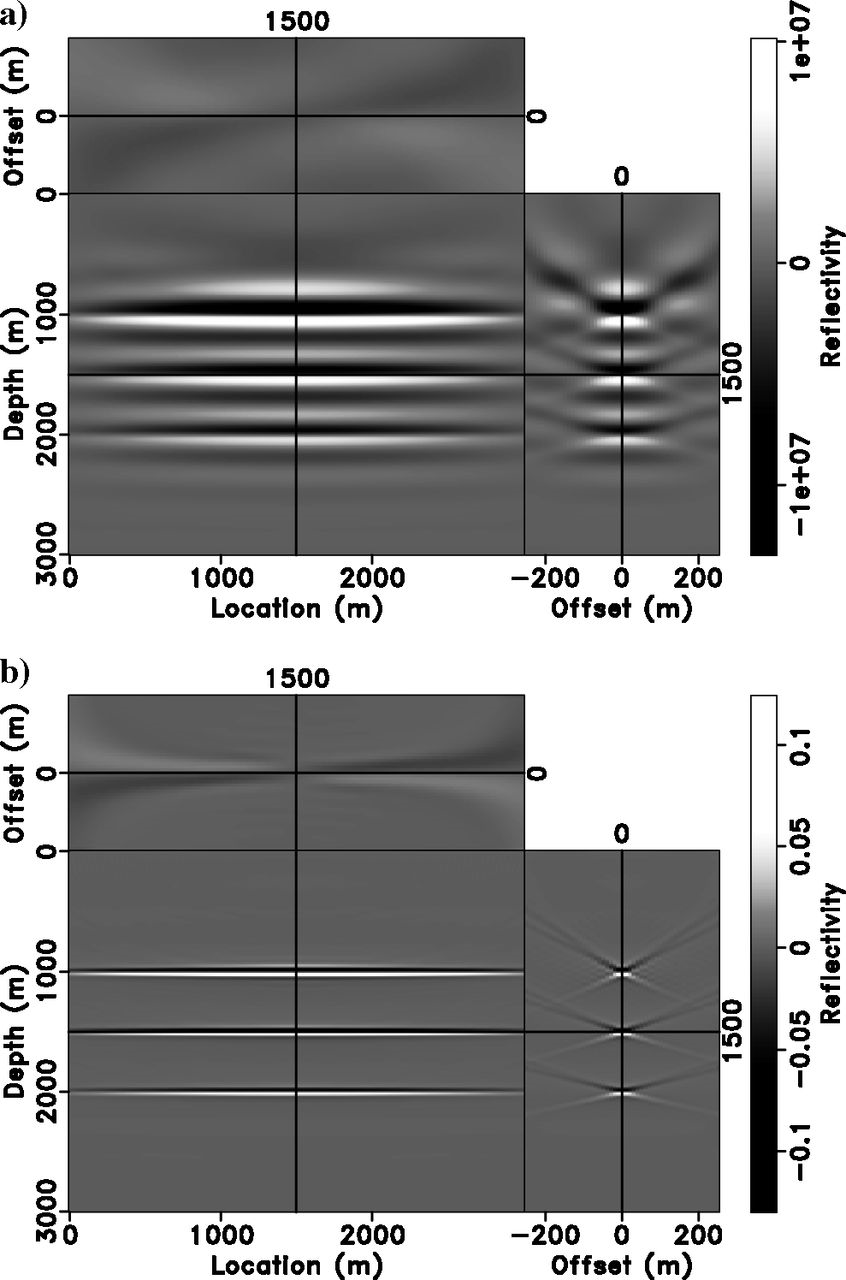
Data Fit Verification
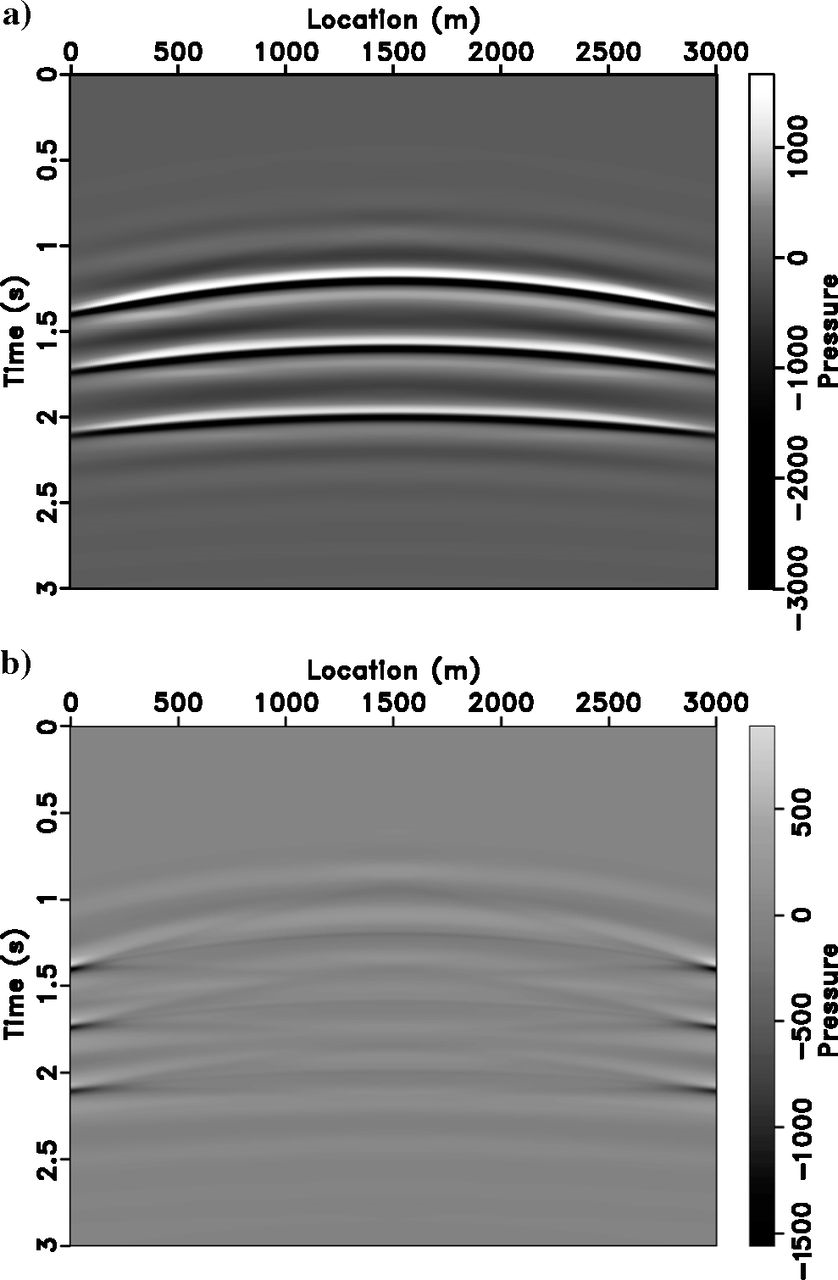
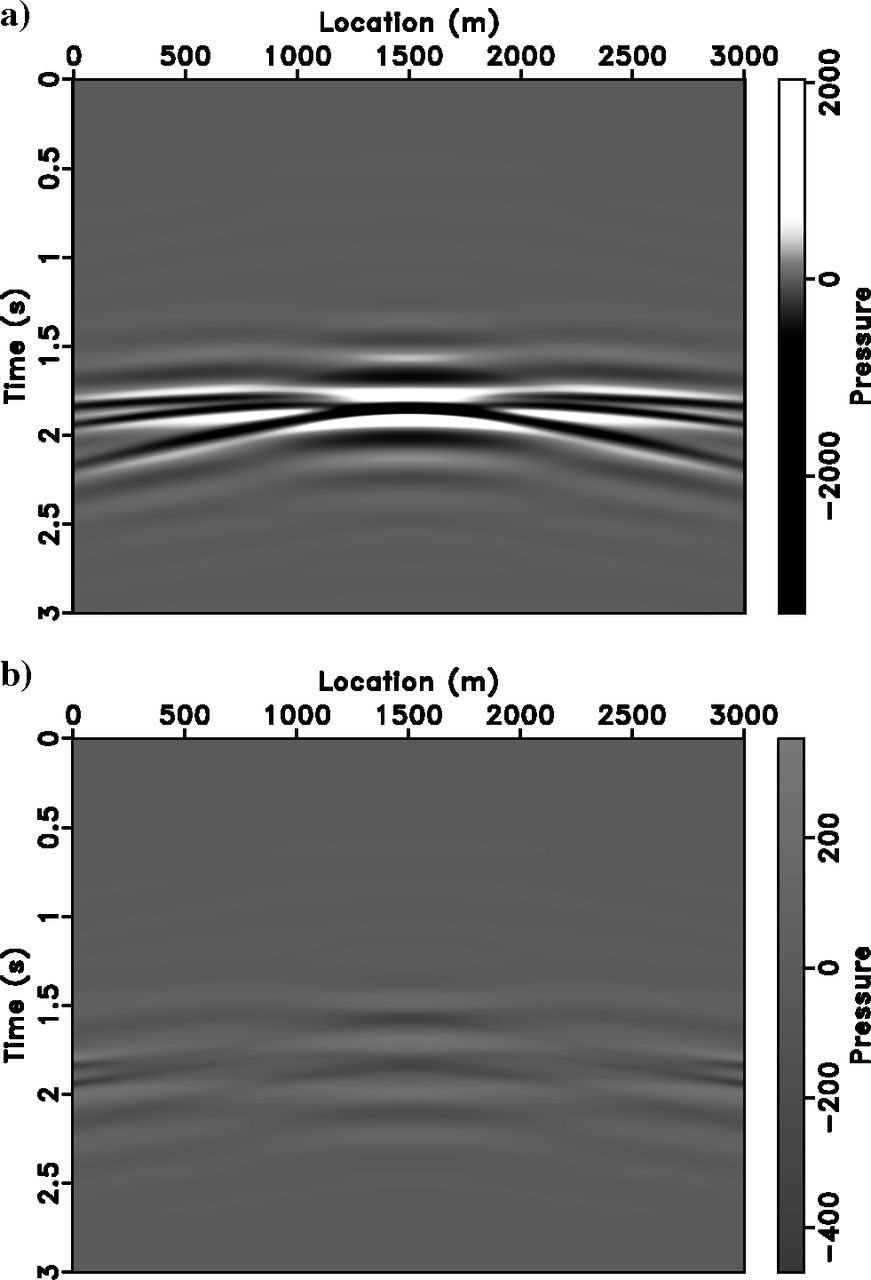
Inversion with Incorrect Velocity
Data Fit with Wrong Velocity
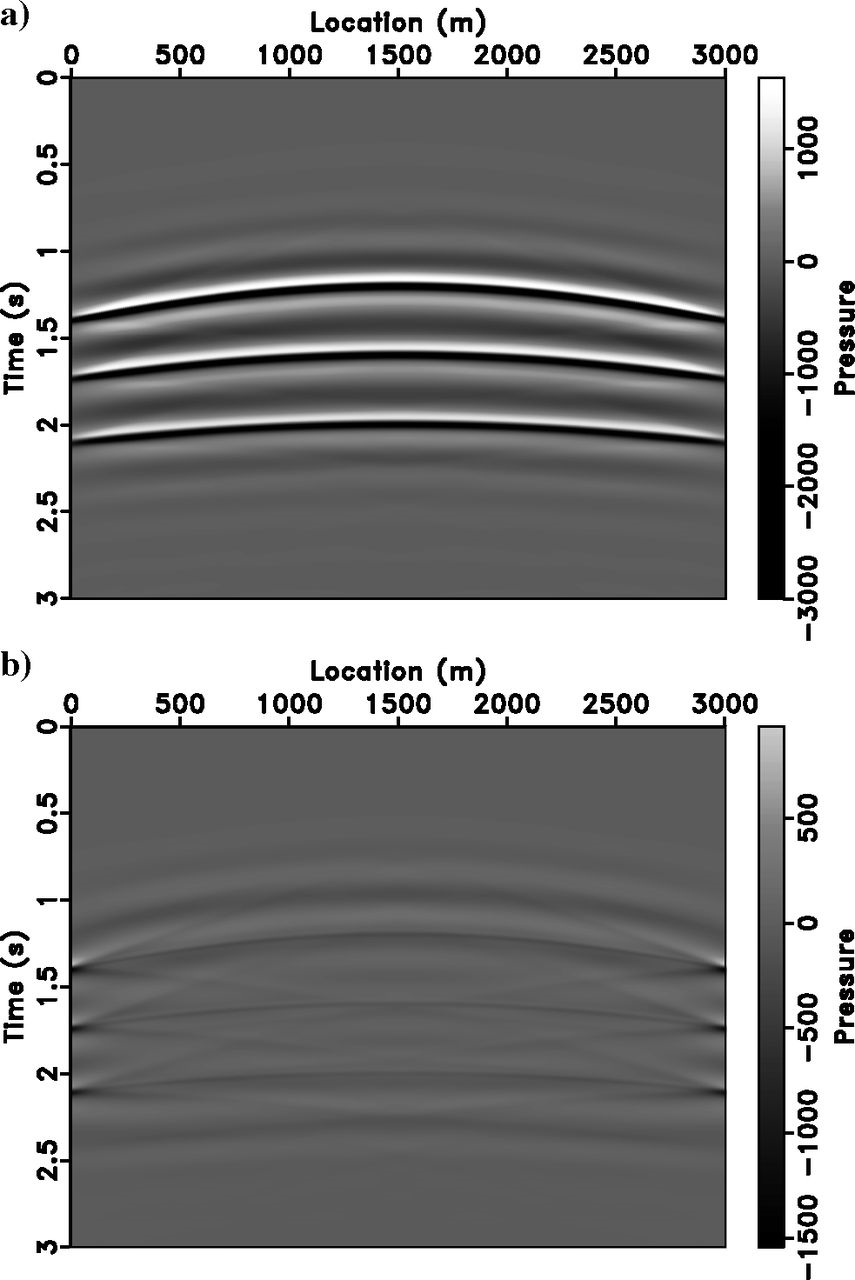
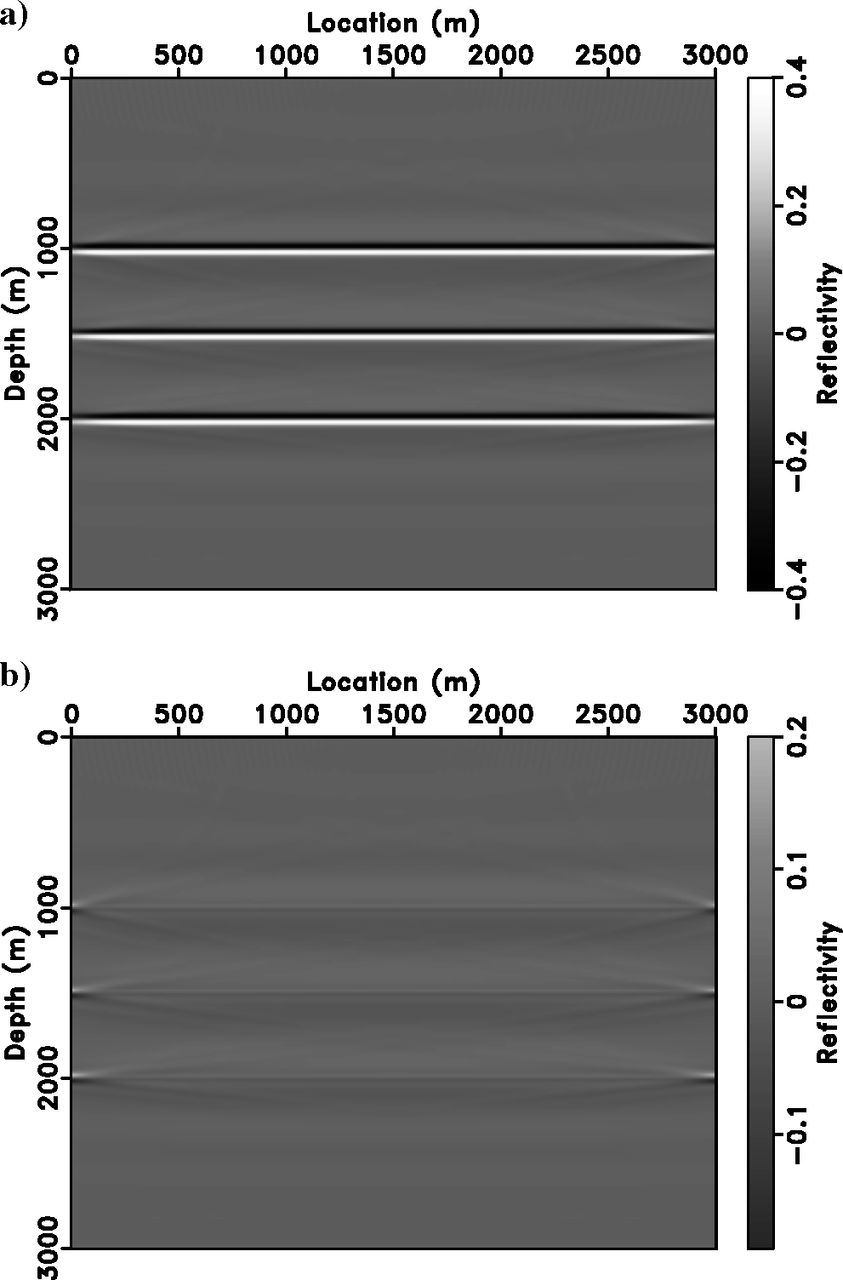
Nonextended Inversion Result
Gaussian Lens Example
Gaussian Lens — Inversion Results
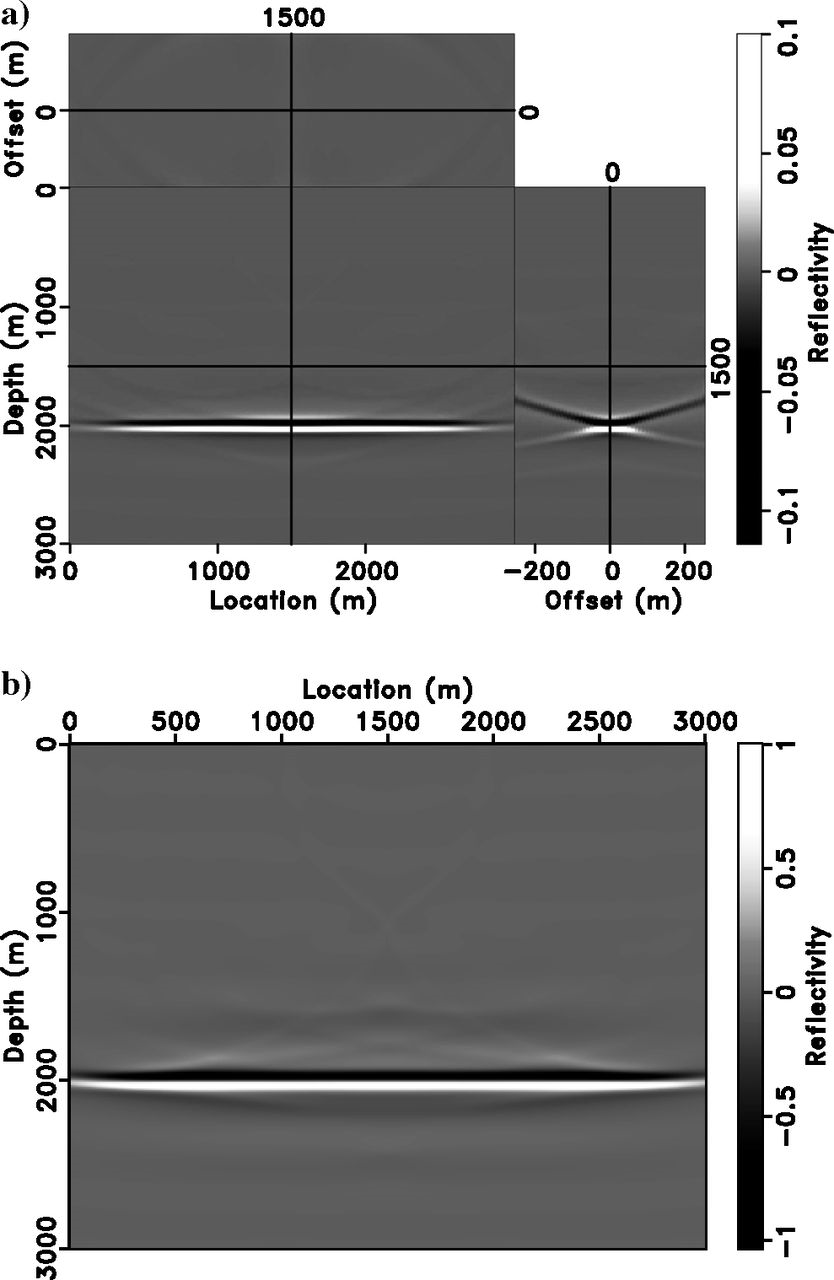
Gaussian Lens — Data Fit
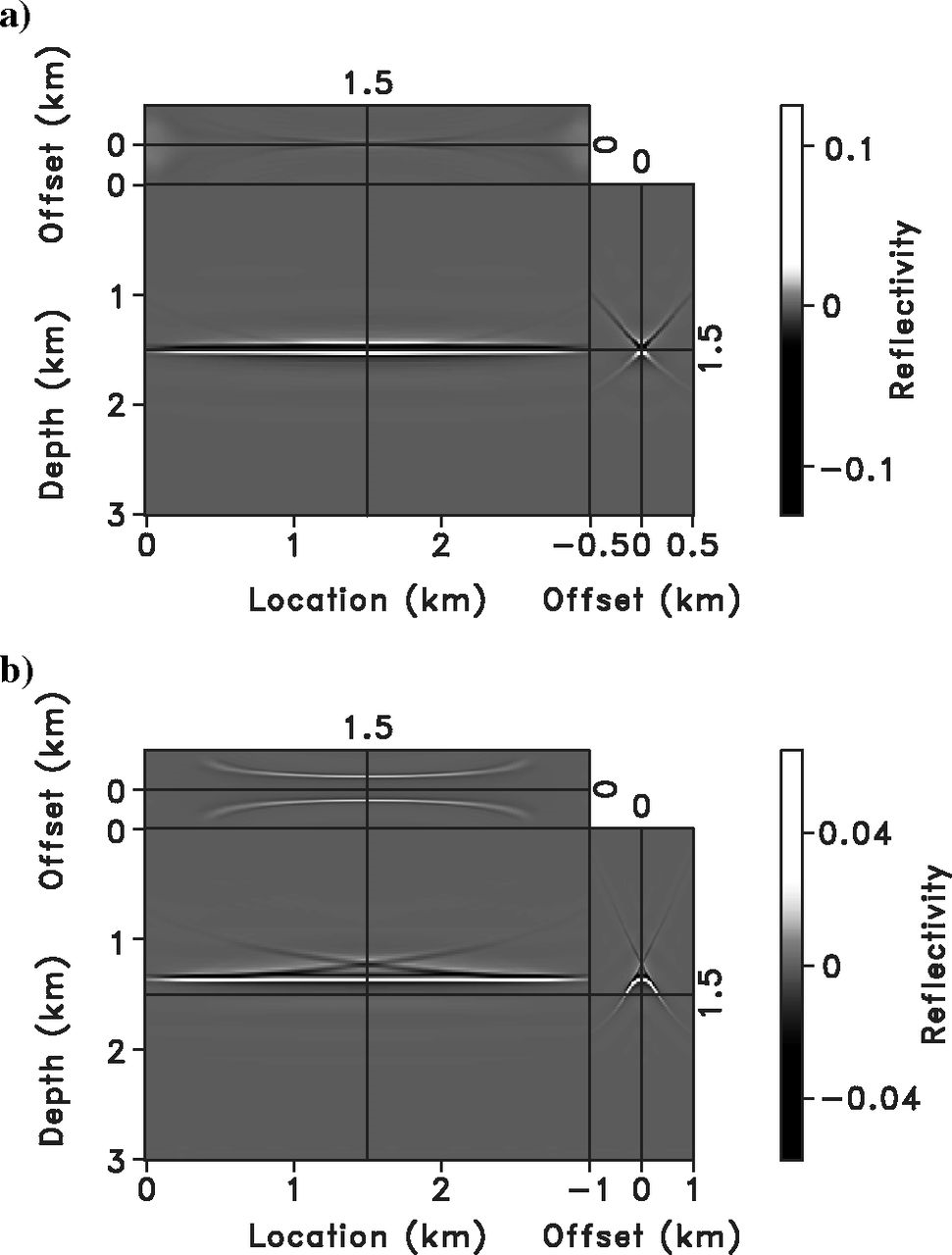
LSM: Correct vs. Wrong Velocity
ELSM: Correct vs. Wrong Velocity
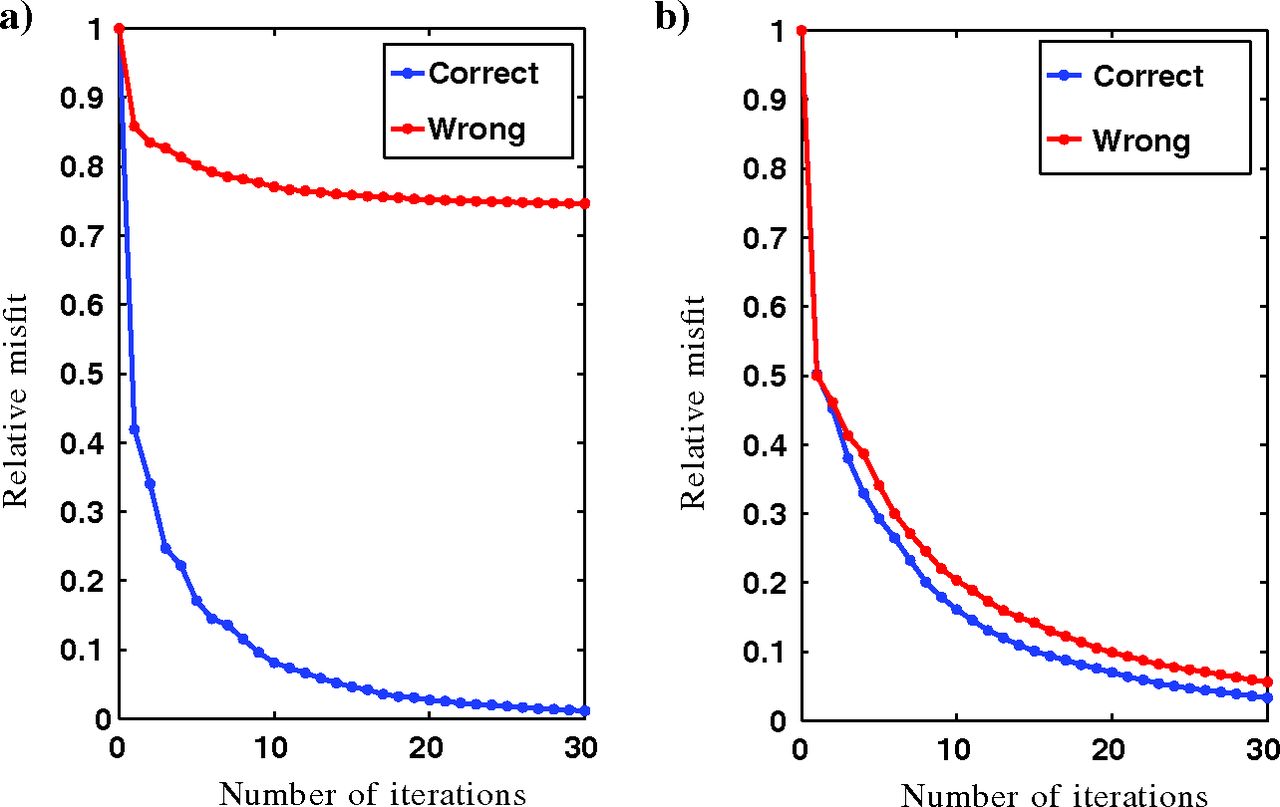
Convergence: LSM vs. ELSM
Simple Model — CG vs. WCG
ELSM Results — CG vs. WCG
Physical Image from WCG
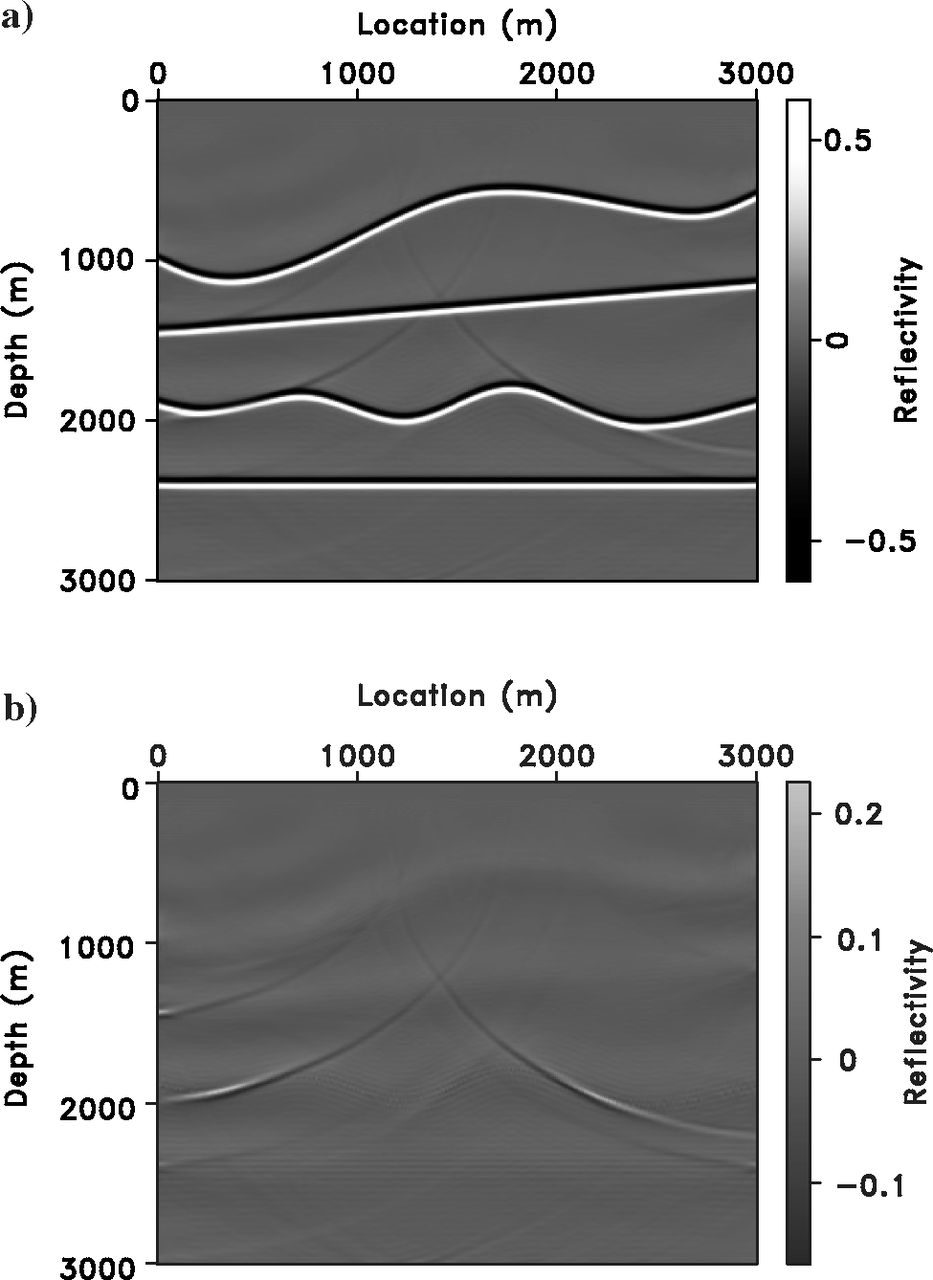
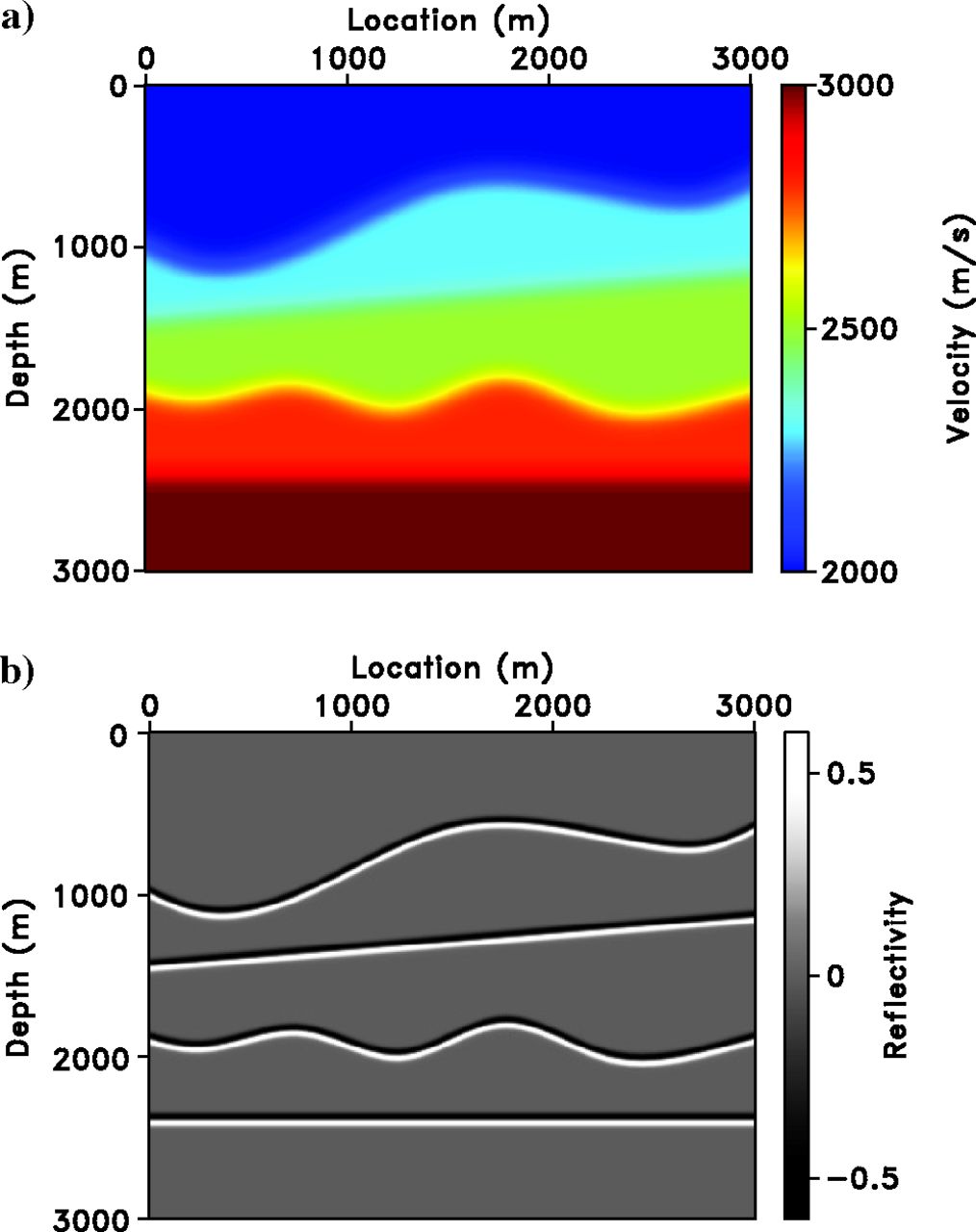
Marmousi Model Setup
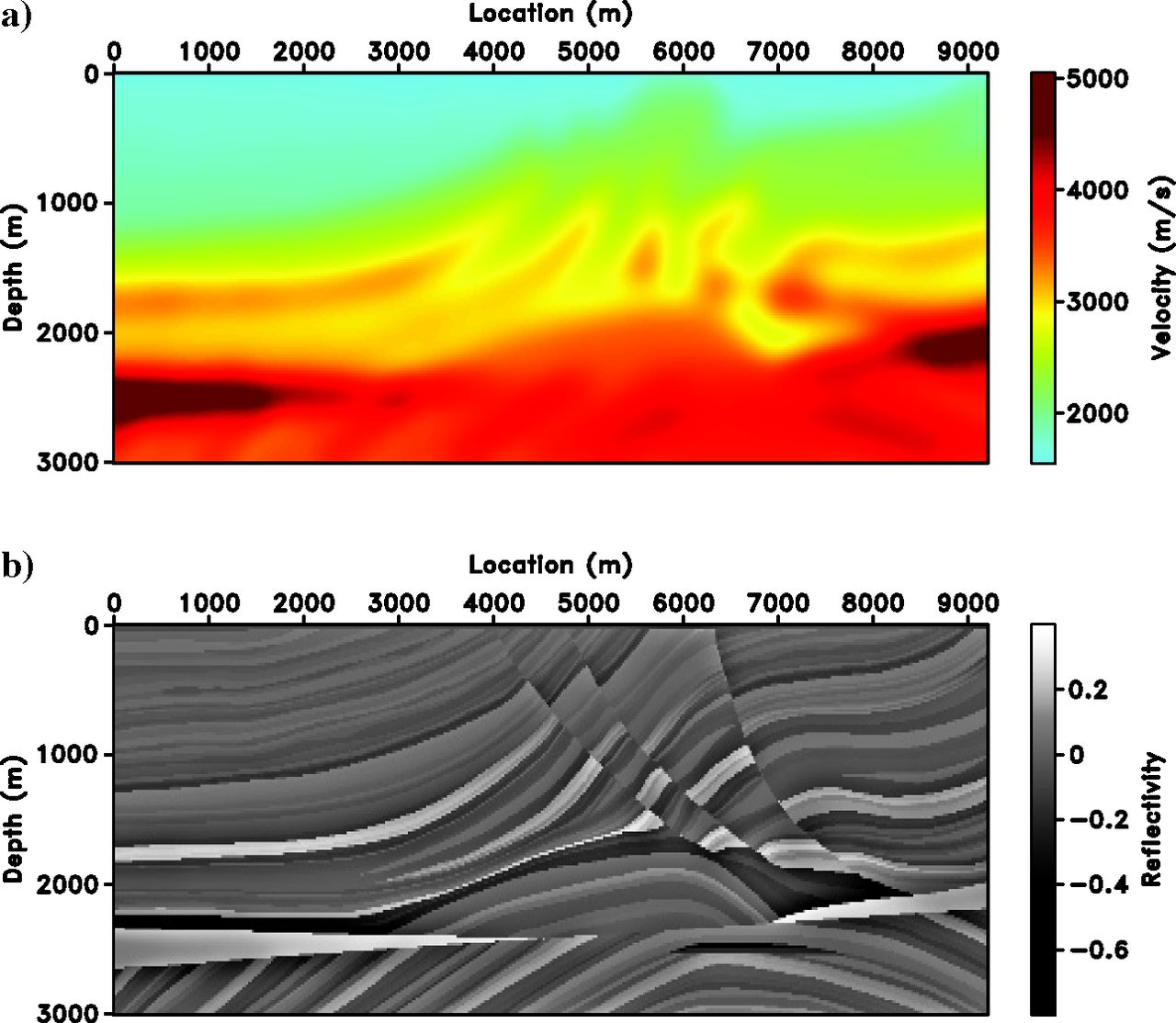
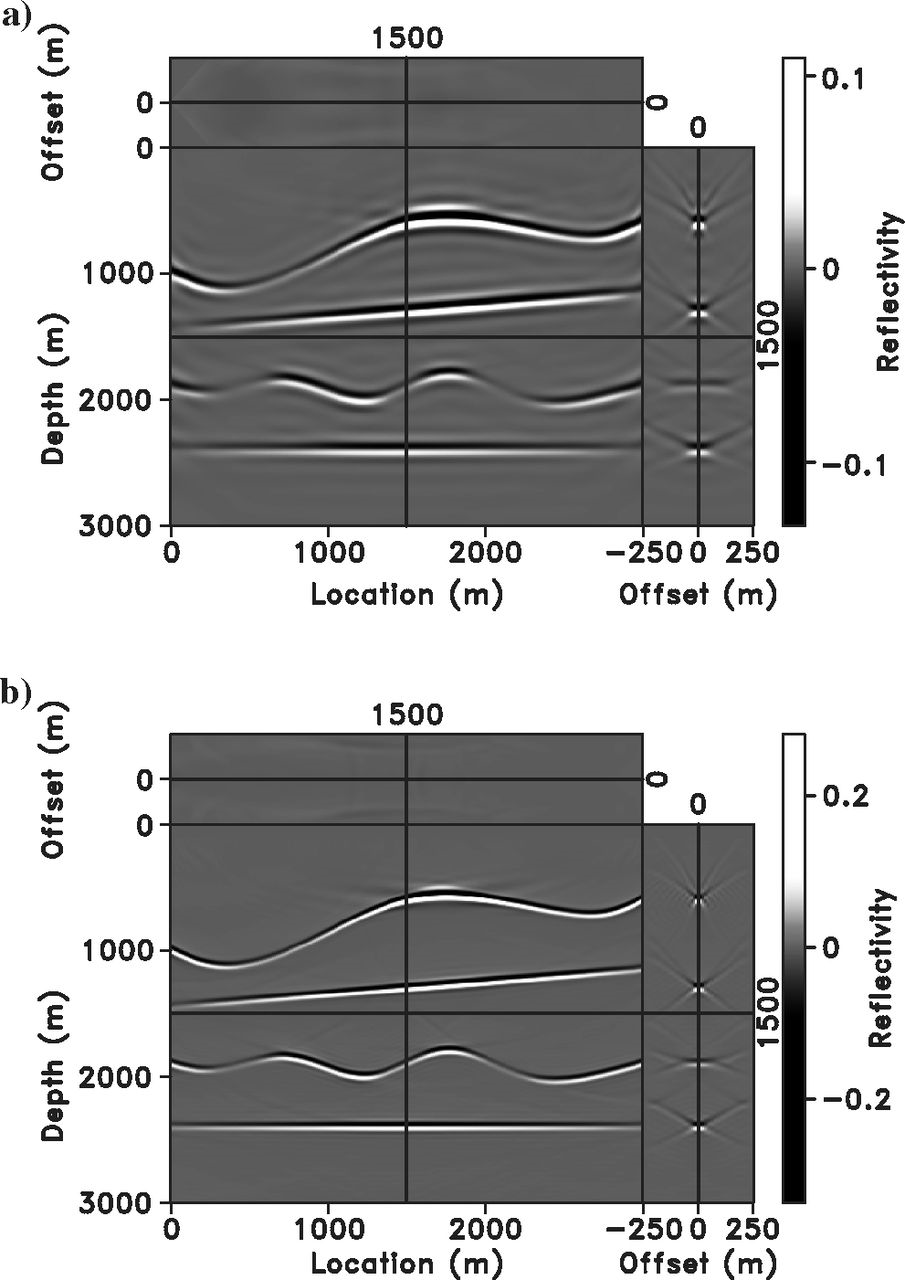
Marmousi — ELSM Results
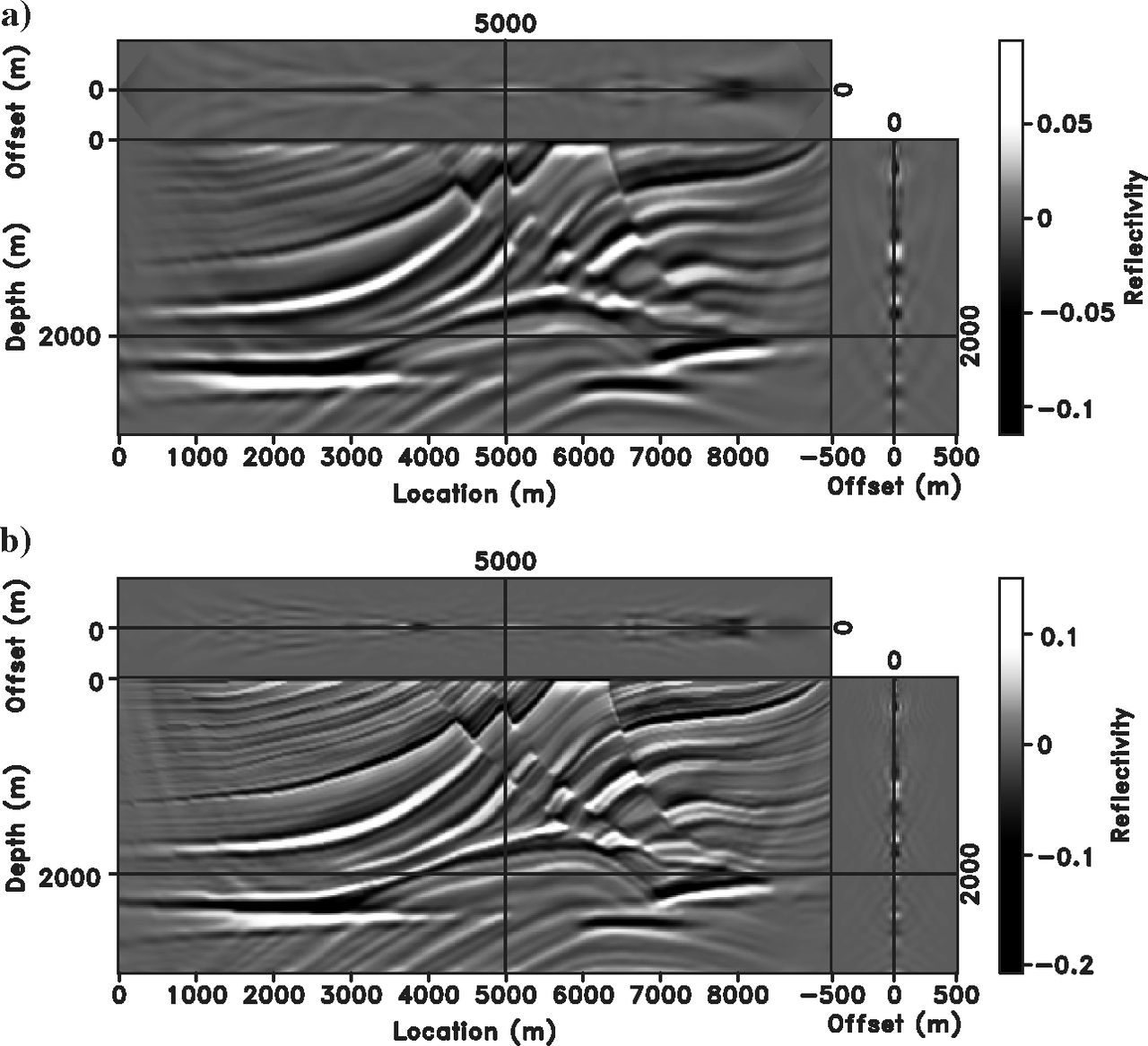
Marmousi — Stacked Images

Marmousi — Data Fit
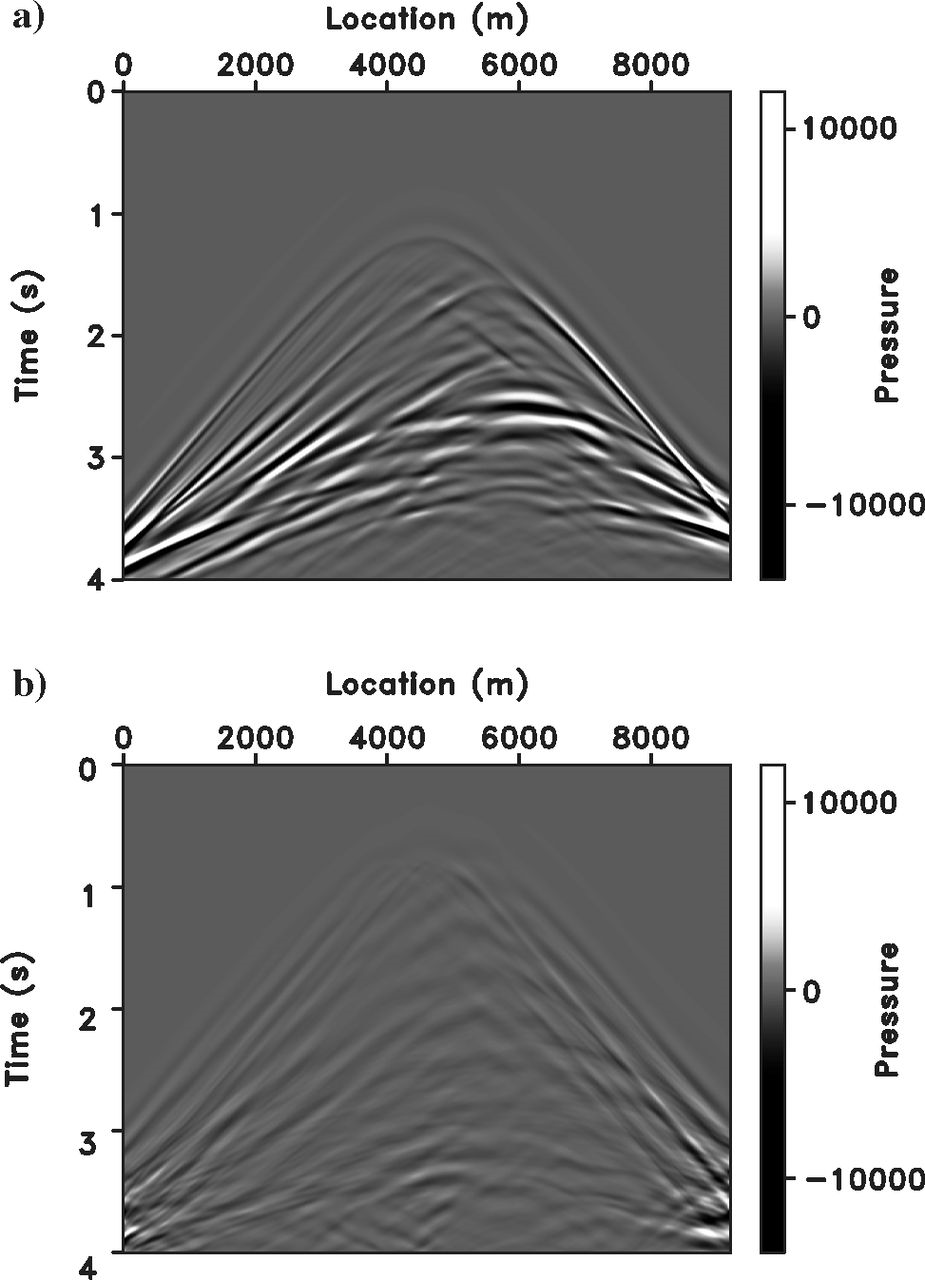
Tip
The residual is amplified by a factor of 10 — the actual misfit is very small, confirming accurate data fit.
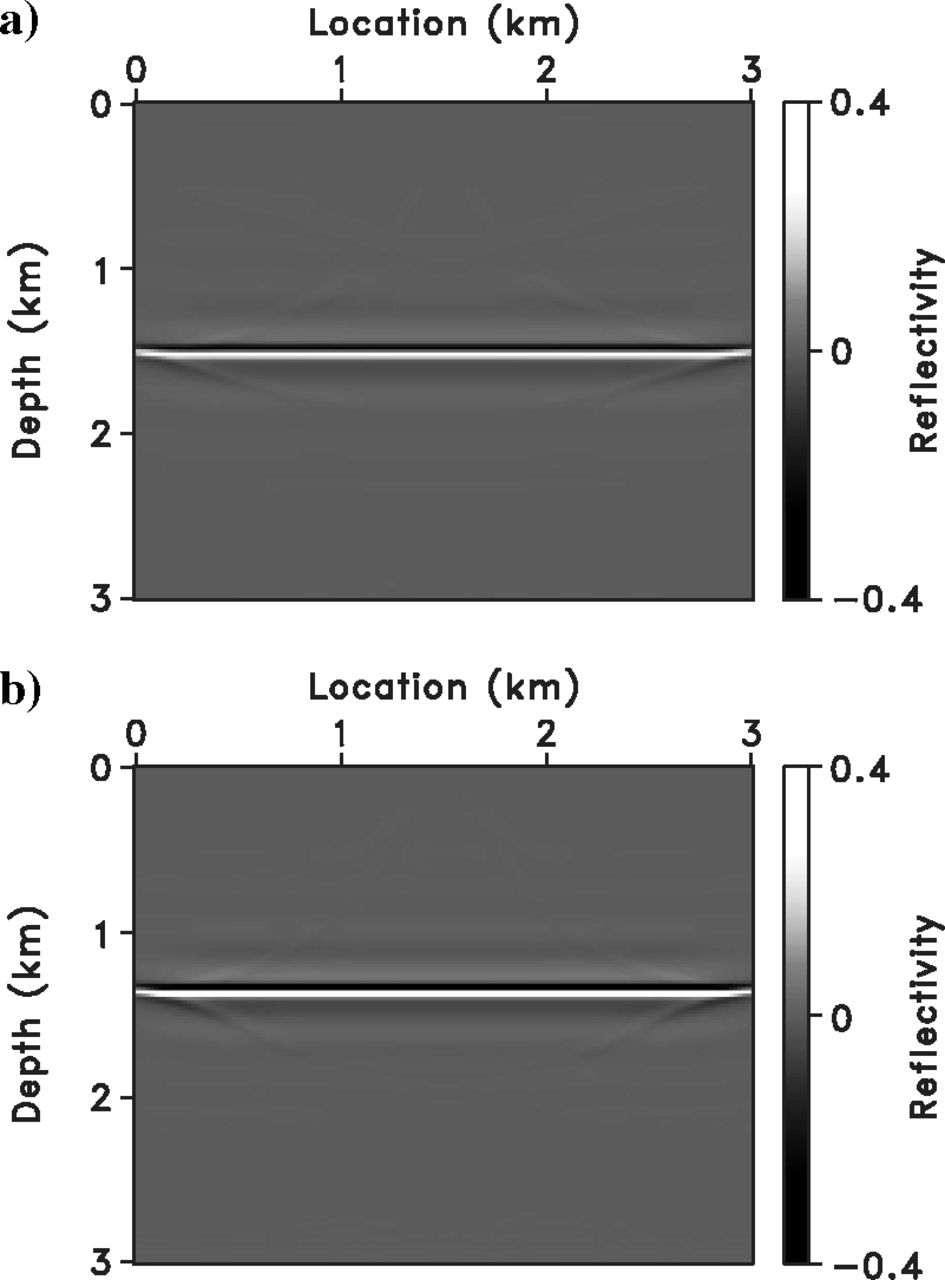
Marmousi — Wrong Velocity
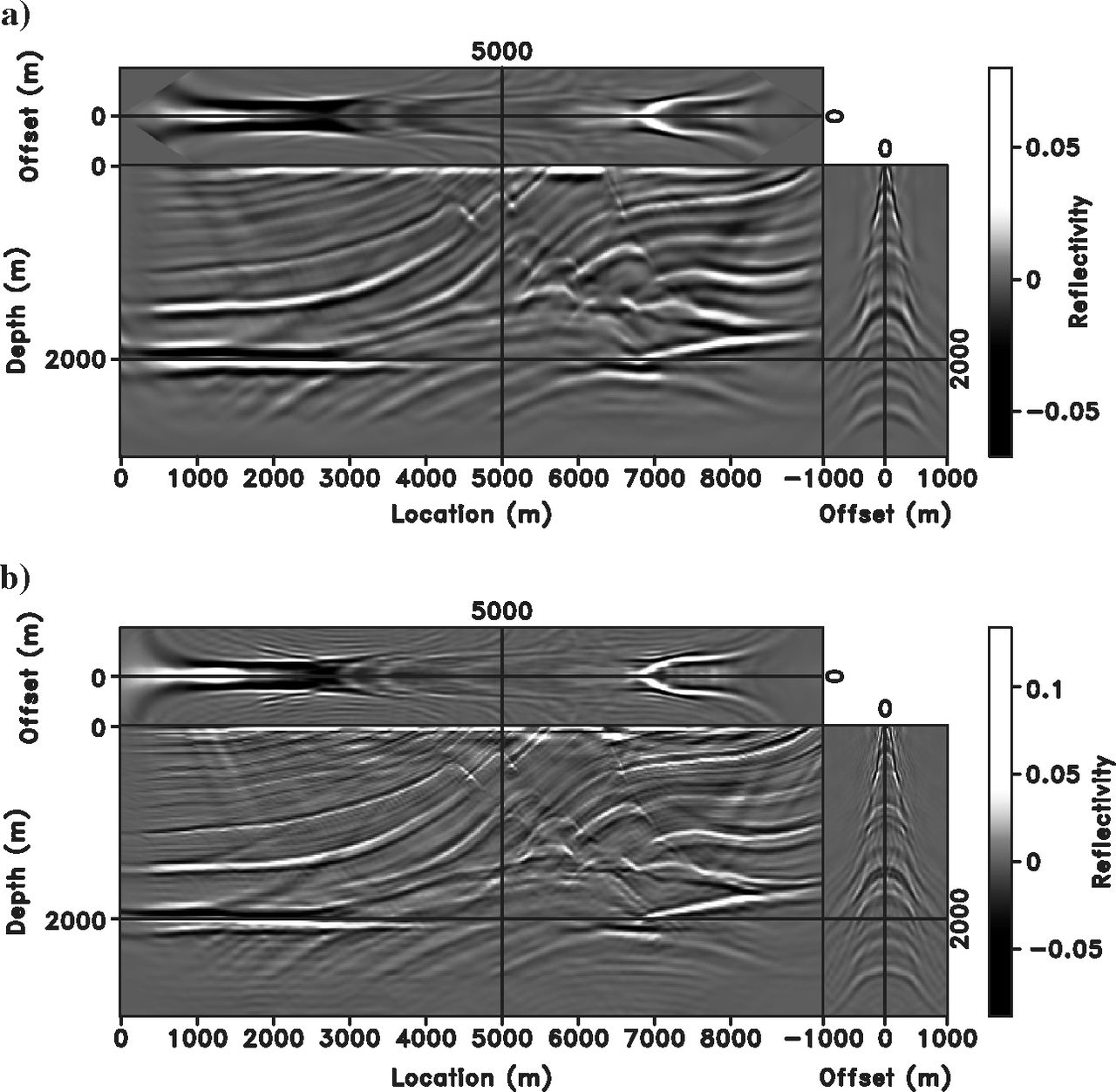
Important
The image is not focused for the poor background velocity, yet data is fit (as in Figure 14). The offset range must be doubled (\([-1000, 1000]\) m) to accommodate the velocity error. This is the key feature exploited for velocity analysis.
Marmousi — Convergence Comparison
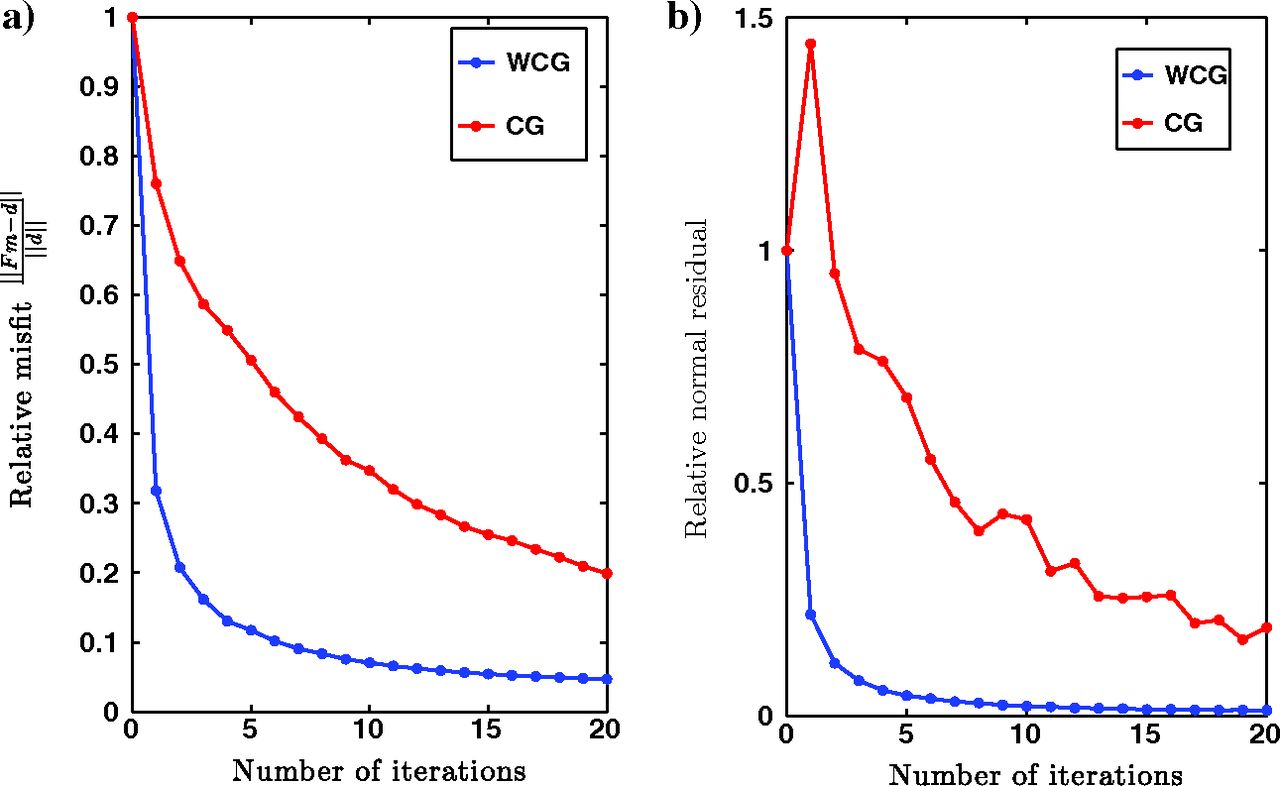
Note
The convergence behavior with wrong velocity is very similar to the correct velocity case — WCG acceleration is robust to velocity error.
RTM vs. Inversion — Objective Function
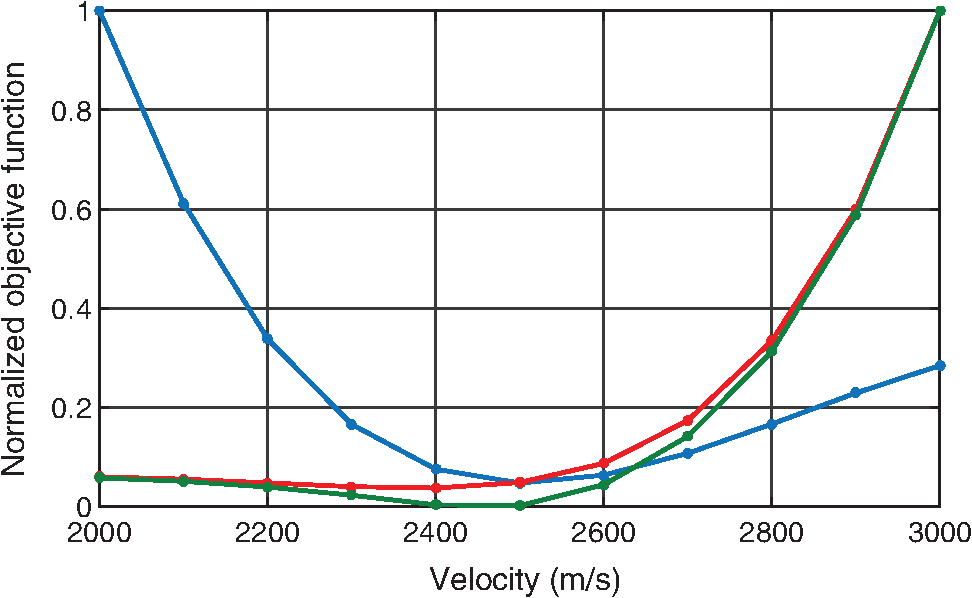
Critical observation
The MVA objective (red) has its minimum shifted to 2400 m/s — the wrong velocity! The IVA objective (blue) correctly minimizes at 2500 m/s. The so-called “gradient artifacts” are actually a problem of the objective function, not the gradient.
Velocity Update Results
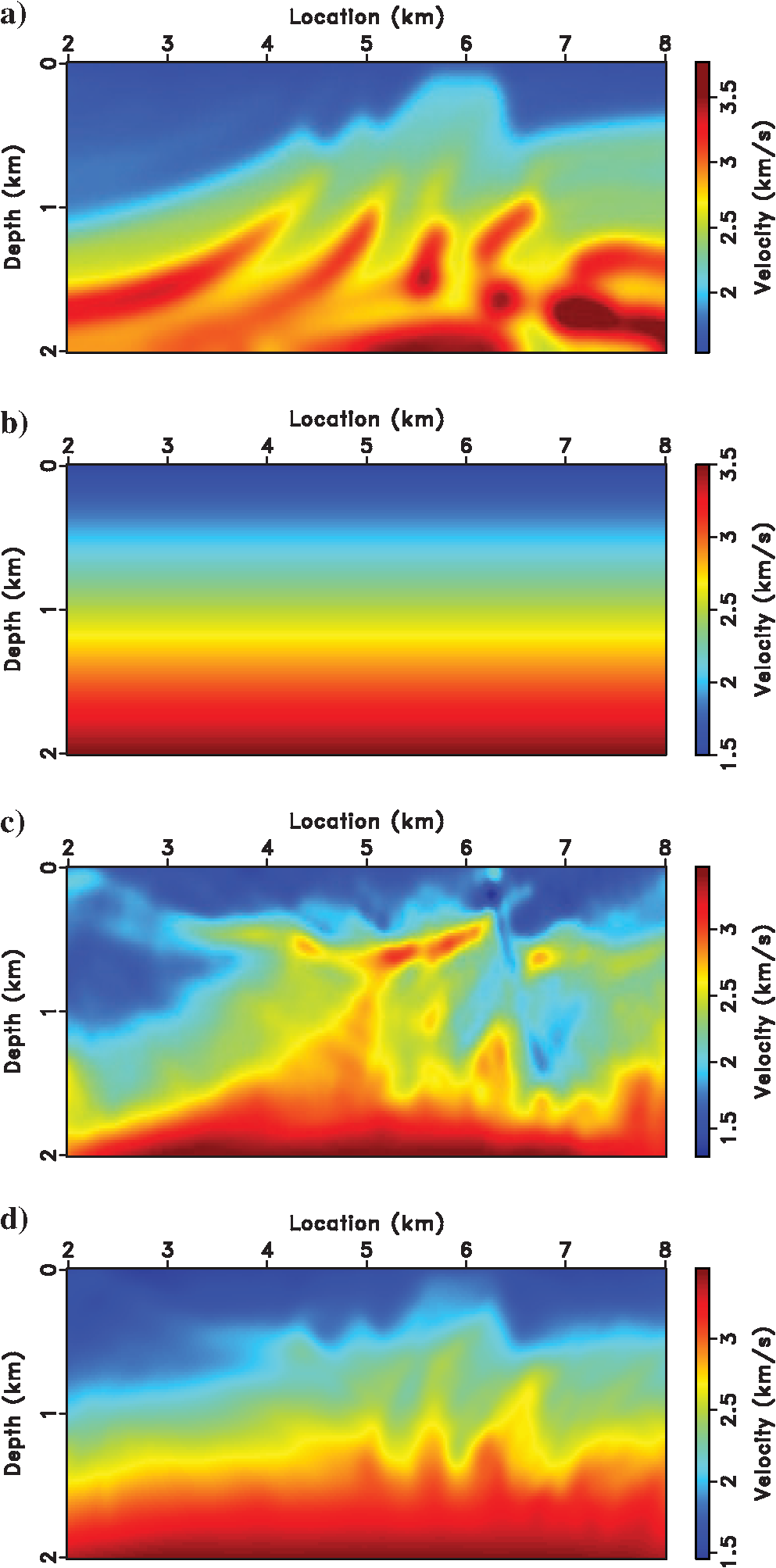
Zero-Offset Images — Velocity Quality
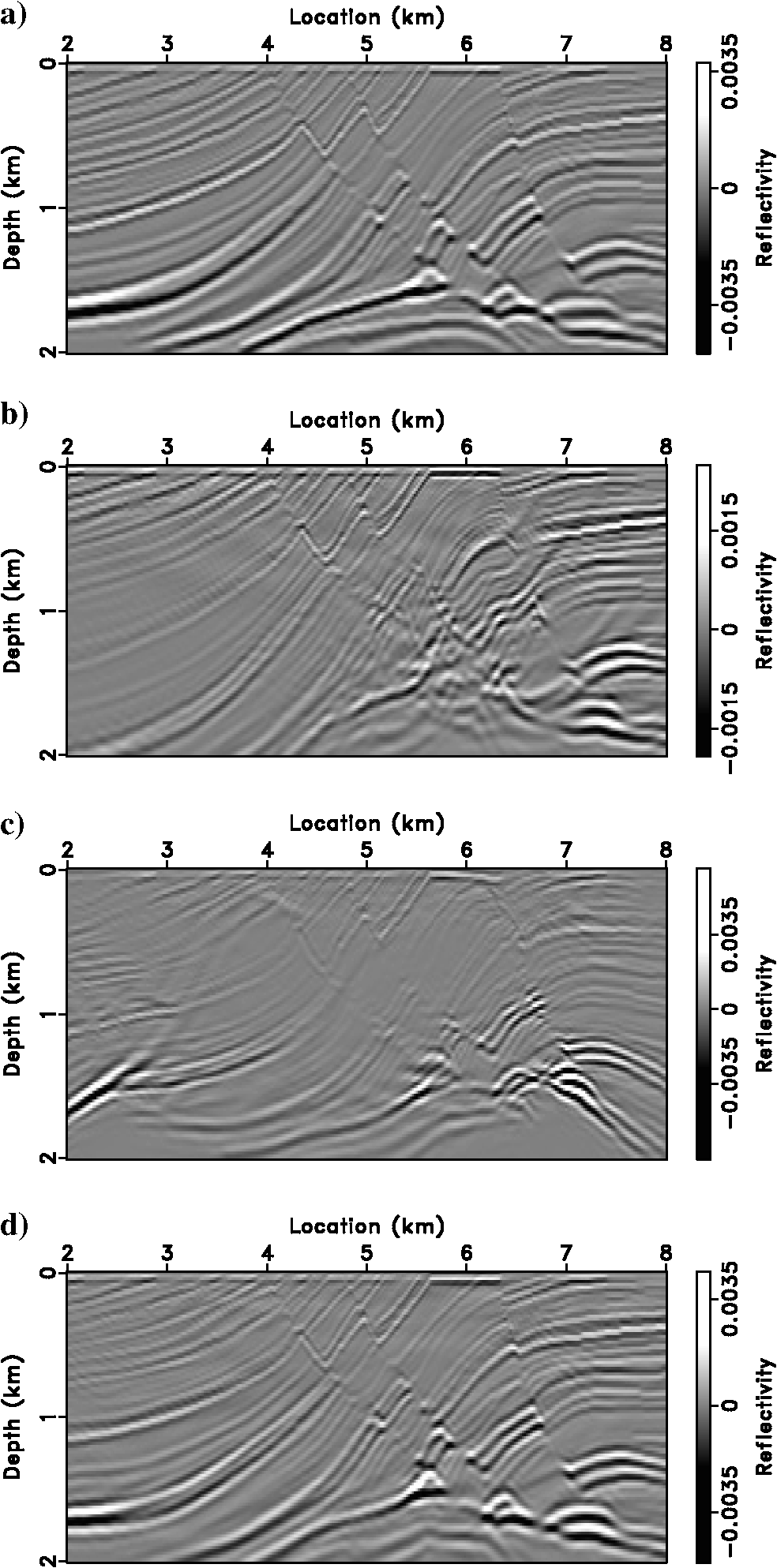
Image Gathers — Focusing Quality
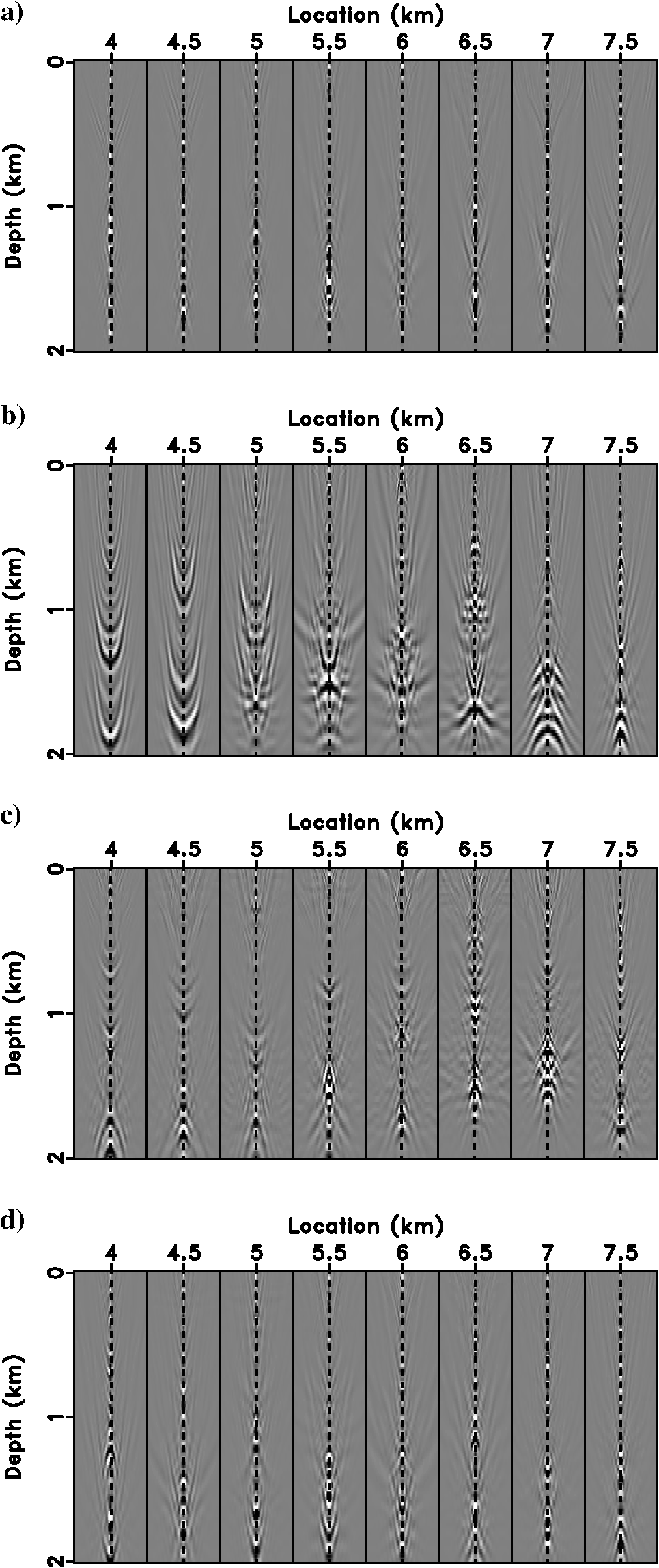
The Artifact Problem
When RTM (the adjoint) is used instead of inversion, artifacts corrupt the velocity update (Hou and Symes 2018):